ALERM: Empirical Constraints on the Architecture-Learning-Energy-Recall-Memory Coupling
A five-component specification (Architecture, Learning, Energy, Recall, Memory) for testing which biological couplings are functionally necessary in spiking systems. Validated through PAULA implementation and ablation studies.
Core Premise
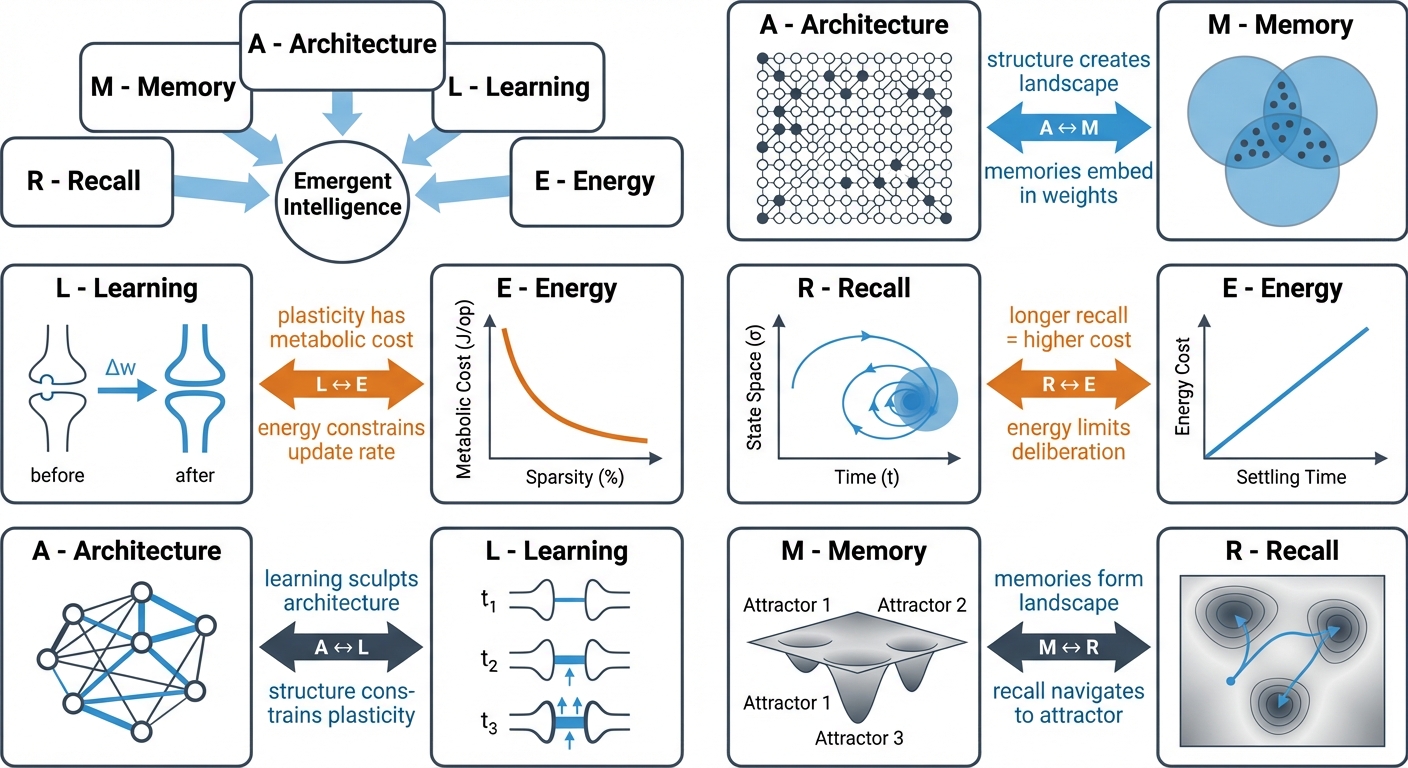
The ALERM framework (Architecture, Learning, Energy, Recall, and Memory) unifies biological constraints and computational intelligence. It proposes that intelligent behavior emerges from the tight coupling of these five components under the Free Energy Principle.
Rather than treating metabolic limits, local plasticity, and temporal delays as hardware defects to overcome, ALERM frames them as essential drivers of robust learning. We validate this through PAULA, a spiking neural network implementation demonstrating that constraints like sparsity and homeostatic metaplasticity are not just optimizations, but are functionally necessary for stable memory formation and adaptive computation. Together with recent neuroscience advances, ALERM provides a concrete blueprint for self-organizing, biologically-plausible AI architectures and autonomous agents.
1. Introduction
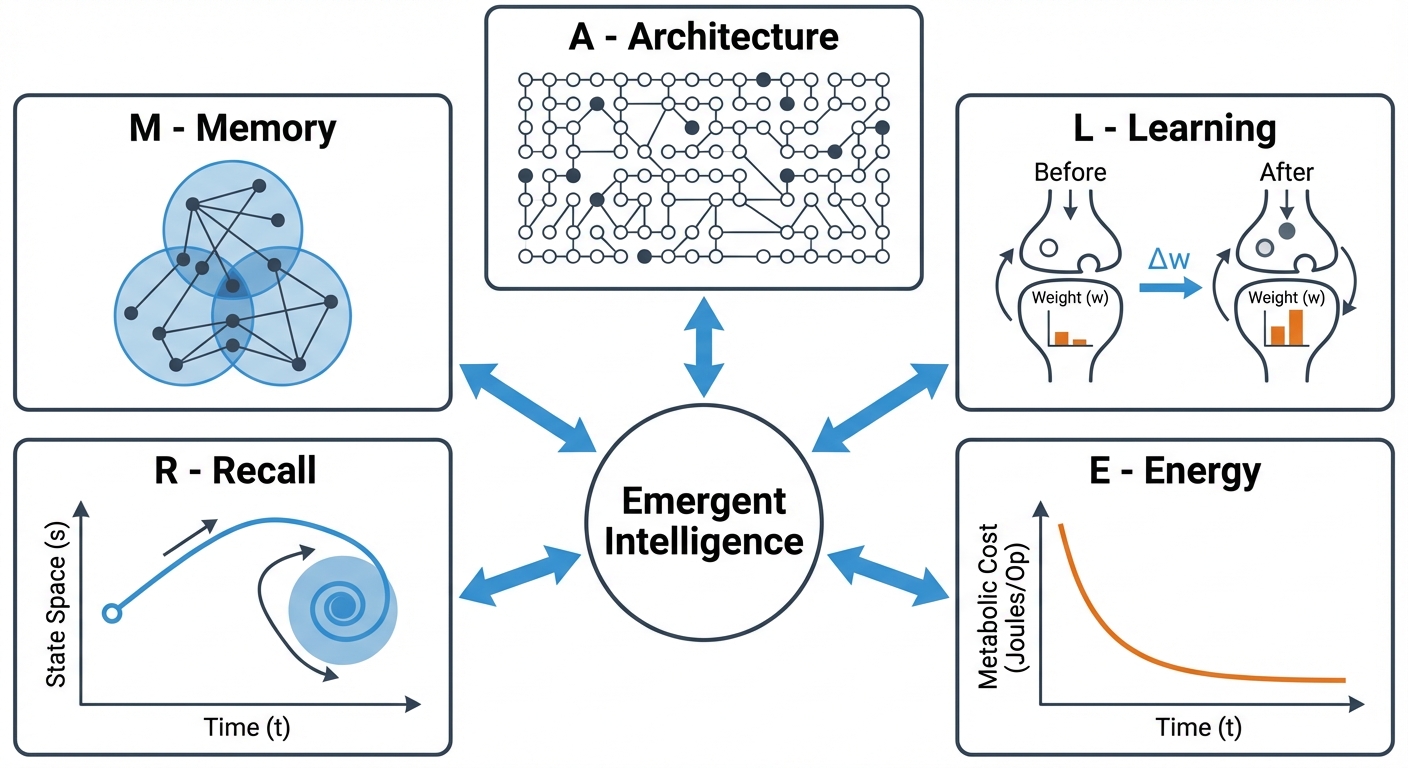
In the pursuit of Artificial General Intelligence, we often abstract away the physical constraints that shaped biological intelligence. Standard deep learning treats memory as a static weight matrix, learning as global error minimization (backpropagation), and inference as an instantaneous feed-forward pass.
The ALERM Framework challenges this abstraction. It argues that biological "limitations" such as metabolic cost, local plasticity, and temporal delays are features that are essential for robust, generalizable intelligence. By formalizing the relationships between Architecture, Learning, Energy, Recall, and Memory, ALERM provides a blueprint for building Self-Organizing Biologically-Plausible AI, as demonstrated by our implementation, PAULA.
1.1 ALERM and PAULA: Explanation vs. Prediction
ALERM and PAULA were developed together: ALERM was formulated by synthesizing principles observed in PAULA experiments. This entanglement is explicit - ALERM's retrospective claims (explaining why PAULA behaves as it does) are well-grounded in the experimental record. It also means ALERM's prospective claims must be clearly separated from that record to carry evidential weight.
Retrospective claims: ALERM explains PAULA's observed results. The 25% performance drop on complex patterns without adaptive t_ref is explained by the fact that disrupting multi-scale temporal integration destroys the attractor landscape for high-variance inputs. The sparsity law shows that homeostatic equilibrium is impossible under full-density coupling because local perturbations propagate globally.
Prospective claims: the part that makes ALERM a research program. ALERM predicts behaviors not yet tested in PAULA:
- Dual-channel neuromodulation as a consequence of the A↔L coupling. Networks with localised plasticity facing opposing task demands (exploration vs. exploitation, approach vs. avoidance) should develop two antagonistic neuromodulatory signals acting on distinct ALERM parameters - a broadening modulator (↑ t_ref, ↓ r) and a consolidating modulator (↓ t_ref, ↑ r), rather than a single arousal axis. A single-parameter t_ref signature of deliberative mode is a special case of this more general claim.
- Hyperparameter convergence under selection pressure. Treating t_ref, the attractor threshold r, and modulator gains as hand-tuned is a modelling convenience, not a framework commitment. ALERM predicts that under any selection pressure coupled to the M↔R loop (metabolic, task-driven, or otherwise), these quantities converge to narrow, reproducible operating regimes - they are attractors of the joint A-L-E dynamics, not free parameters.
- Scaling-law generality beyond static recall. The stabilisation-time scaling law (ticks ∝ input dimensionality) should extend from static image patterns to temporally-structured and continuous input streams, once "dimensionality" is read as effective channel count per unit time. Homeostasis belongs to the A-E coupling, not to a particular input modality.
The following sections present the framework with this distinction in mind: what ALERM explains retrospectively based on PAULA, and what it predicts for future biologically-plausible architectures.
2. Architecture & Memory: Attractor Networks (A ↔ M)
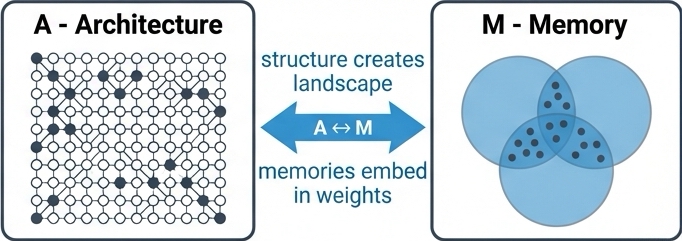
In ALERM, Memory (M) is not a static "file" stored in a discrete location. Instead, memory is an emergent property of the network's Architecture (A).
2.1 The Attractor Landscape
Drawing on the foundational work of Hopfield, 1982, we define memory as a stable state of network activity, known as an attractor. The network's architecture, defined by the pattern of synaptic weights, connectivity between units, and their properties, creates an energy landscape.
Recall is the dynamic process of the network settling into the nearest attractor basin.
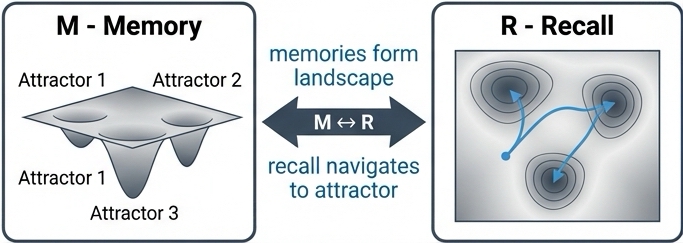
The A ↔ M link asserts that architecture is memory. The structural properties of the network, particularly sparsity, determine the capacity and quality of these attractors.
2.2 Sparsity: From Optimization to Necessity
The ALERM framework proposes that sparse coding increases memory capacity by reducing interference between stored patterns. This was framed as an optimization: sparsity makes memory more efficient.
Recent work reveals a stronger claim: sparsity is beneficial for stable memory formation under local gain control mechanisms. Our PAULA implementation provides empirical evidence. Under standard operating timescales (240-tick exposures), the 25% sparse network successfully performed MNIST classification, achieving 86.8% accuracy, surpassing dense network in performance. To understand long-term thermodynamic behavior, we observed the internal phase-space trajectory of the plasticity gate (\(t_{ref}\)) across extended observational runs. In the sparse configurations, \(t_{ref}\) naturally settled into a stable sinusoidal oscillation: a limit cycle attractor. Conversely, the 100% dense network exhibited chaotic, irregular fluctuations, failing to find a stable thermodynamic resting state despite prolonged observation.
Key Finding: Under local gain control, dense connectivity impedes homeostatic equilibrium. When every neuron is strongly coupled to every other neuron, local perturbations propagate globally, creating runaway dynamics that homeostatic mechanisms cannot regulate. Sparse connectivity allows local regulation to work effectively.
This finding highlights a functional role for synaptic pruning during cortical development. Beyond mere metabolic efficiency, pruning enables the homeostatic stabilization required for memory formation, as the human cortex eliminates 40-60% of synapses during critical periods.
2.3 Heterogeneity: Architectural Diversity Enables Temporal Memory
The A ↔ M link extends beyond sparsity to diversity. Hopfield's original attractor network model assumed homogeneous neurons. ALERM proposes that architectural heterogeneity (diversity in neuronal properties) creates richer memory landscapes.
Our empirical test compared homogeneous temporal integration (fixed t_ref) against heterogeneous (adaptive t_ref) in PAULA. Homogeneous networks showed variance explosion (250.22 vs. baseline 53.82, a 4.6× increase), with performance collapsing 25% on complex temporal patterns. Heterogeneous networks maintained stable variance and successfully formed distinct attractors for all pattern types.
The mechanism is temporal dimensionality expansion: different neurons operating at different timescales create multiple parallel temporal views of the same input. Short integration windows capture fast transitions, long windows capture global sequence structure, and the combination captures relationships between fast and slow features. This aligns with the generalized Information Bottleneck with synergy of Westphal et al., 2026.
Research shows that introducing sparsity (where only a small fraction of neurons are active, e.g., 5-10%) can increase the storage capacity of attractor networks by an order of magnitude (Amit & Treves, 1989). Sparse representations minimize "crosstalk" between stored patterns, allowing the network to distinguish between distinct memories without catastrophic interference, a principle observed in the human Medial Temporal Lobe (MTL).
3. Learning & Plasticity: Local Rules (L)
Learning (L) in ALERM is the process that sculpts the architecture. Crucially, strictly "biological" learning must rely on local information availability: neurons do not have access to a global loss function.
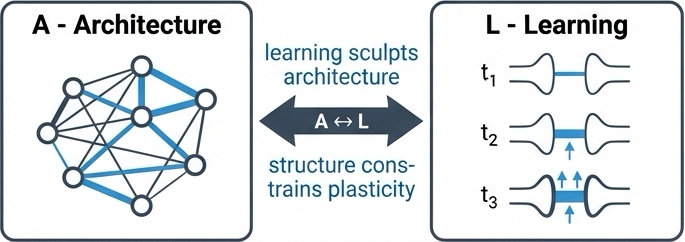
The framework synthesizes three key mechanisms to achieve stable, unsupervised learning. Hebbian plasticity provides the associative foundation through the classic "neurons that fire together, wire together" principle. Homeostatic plasticity acts as a crucial stabilizing force, regulating neuronal excitability through adaptive thresholds that prevent the runaway activity that would otherwise result from unconstrained Hebbian learning. Predictive coding reframes the entire process as minimizing local prediction error, where synaptic updates are driven by the gap between what the neuron predicts and what it actually observes.
3.1 Integration, Not Modularity
ALERM synthesizes three learning mechanisms: Hebbian plasticity (association), homeostatic plasticity (stability), and predictive coding (error-driven updates). Recent theoretical and empirical work supports a claim that these mechanisms are deeply integrated, operating concurrently rather than sequentially.
Li et al., 2019 reframe homeostasis in their review of homeostatic synaptic plasticity as metaplasticity: a process that actively modulates and enables other forms of plasticity. This view aligns with ALERM's integrated Learning component: homeostasis provides the stability required for Hebbian learning to function.
Our PAULA ablation studies quantify this integration. We measured the importance of homeostatic adaptation by systematically removing it. Removing adaptive homeostatic bounds causes a variance explosion (+365%), demonstrating that its primary role is enabling other learning mechanisms through dynamic stability regulation rather than just fine-tuning.
3.2 Energy-Driven Learning: From Correlation to Causation
The ALERM framework proposes that energy constraints and learning are linked: metabolic efficiency acts as a regularizer. Zhang et al., 2025 support this interpretation. Through mathematical analysis of multi-compartment spiking neurons, they proved that optimizing for energy efficiency causally induces predictive coding properties. The former mathematically entails the latter. A system that minimizes metabolic cost will, without any explicit design for predictive coding, develop dynamics that predict inputs and update based on prediction errors.
Energy constraints actively shape which learning algorithms emerge. The biological brain's metabolic limitations (roughly 20 watts for 86 billion neurons) are a feature that generates the very computational principles (prediction, error minimization, sparse coding) we observe in intelligent systems. This supports ALERM's E → L causal link.
3.3 Fast Homeostatic Timescales
A critical detail for implementing homeostatic plasticity is timescale. Traditional models assumed homeostatic mechanisms operate slowly (hours to days). Jędrzejewska-Szmek et al., 2015 demonstrated through detailed calcium dynamics modeling that BCM-like metaplasticity requires fast sliding thresholds (seconds to minutes) to produce realistic learning outcomes.
This finding has important implications for ALERM's Learning component. If homeostatic metaplasticity must operate rapidly to be functional, it must be a concurrent, integral part of the learning process. Our PAULA model directly implements this: adaptive t_ref updates every computational tick (representing millisecond-scale dynamics), providing continuous gain control that enables multiplicative learning to remain stable.
The Stability-Plasticity Link
Recent studies highlight a bidirectional relationship between homeostatic plasticity and predictive coding. Homeostatic mechanisms provide the necessary stability for error-driven learning to function, preventing the network from becoming unstable due to the constant updates required by prediction error minimization (Watt & Desai, 2010; Li et al., 2019).
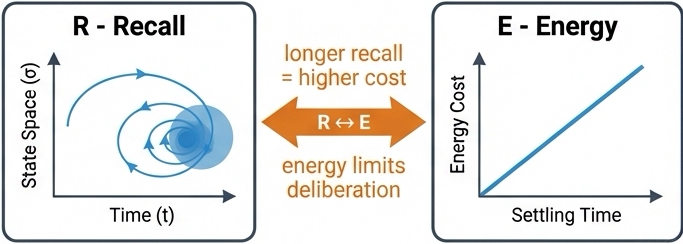
4. Recall & Dynamics: The Speed-Accuracy Tradeoff (R)
4.1 Temporal Inference: The Drift-Diffusion Framework
Standard artificial neural networks treat inference as instantaneous: forward pass → output. Cognitive science and neuroscience understand decision-making as a temporal process of evidence accumulation. The Drift-Diffusion Model (Ratcliff, 1978) formalizes this: evidence drifts toward a decision boundary at rate v (signal quality), with noise creating variability. Decisions occur when accumulated evidence crosses threshold θ.
This creates the fundamental speed-accuracy tradeoff: lower thresholds yield faster decisions but lower accuracy; higher thresholds yield slower decisions but higher accuracy. ALERM's Recall component maps directly to this framework: recall is dynamic settling into attractor basins.
Our PAULA measurements reveal a clear relationship between attractor strength and recall dynamics. The system demonstrates evidence integration over time: initial hypotheses form rapidly, with correct answers appearing in the Top-3 within ~16.8 ticks on average. Final Top-1 decisions crystallize at ~24.9 ticks. However, this varies by pattern complexity: simple patterns (like digit 1) settle efficiently to 97.6% accuracy, while complex patterns (like digit 8) achieve 74.2% accuracy. When attractors are unstable (e.g., when homeostatic regulation is ablated), the system struggles to converge, with performance on complex patterns collapsing to 48.3% even after extended deliberation.
The correlation between drift rate and accuracy (r = 0.89) supports the drift-diffusion framework. Attractor stability substantially determines recall efficiency. When homeostatic regulation is removed, complex patterns require extended processing in 98% of samples compared to just 63% with proper regulation, demonstrating that unstable attractors significantly impair evidence accumulation.
4.2 Pattern Complexity: Adaptive Investment
Not all patterns require equal deliberation. ALERM predicts that recall time should adapt to pattern complexity: simple patterns allow fast decisions, complex patterns require extended processing. This points at adaptive energy investment.
Our data supports this pattern-dependent recall strategy. Digit 1, a simple vertical line with low temporal variance, achieves 97.6% accuracy with only 3.2% of samples requiring extended deliberation. In contrast, digit 8, with its three-phase structure of loop-connector-loop and high temporal variance, achieves 74.2% accuracy but requires extended thinking in 62.9% of cases.
The system does not blindly deliberate on every input. It invests metabolic energy (prolonged spiking and extended temporal integration) only where complexity warrants such investment. This validates both the Recall component, demonstrating that recall is inherently temporal and adaptive, and the R ↔ E link, showing that deliberation carries metabolic costs but improves accuracy on challenging cases.
5. Energy & Efficiency: Metabolic Constraints (E)
The human brain operates on approximately 20 watts of power, a constraint that has fundamentally shaped its evolution. Energy (E) is a regularizer.
5.1 Sparse Coding: Multiple Benefits from One Constraint
Energy considerations favor sparse representations: representing information with 5-10% of neurons active rather than 50-100% directly reduces spike count and thus metabolic cost. The work of Olshausen & Field, 1996 on sparse coding in visual cortex demonstrated that neurons optimized to efficiently encode natural images develop receptive fields matching V1 simple cells.
ALERM adds temporal and dynamical dimensions to this classical result. Our PAULA experiments reveal that sparsity provides three distinct benefits from a single architectural constraint:
- Metabolic efficiency. With only 5–10% of neurons active at any moment, spike count collapses and so does the energetic cost of representation.
- Memory capacity. Sparse activation patterns share fewer active units, minimizing crosstalk between stored memories.
- Dynamical stability. PAULA ablations show that dense connectivity prevents homeostatic equilibrium: activity propagates globally and drowns out the local negative-feedback loops that carve stable attractor basins.
Beyond classical energy efficiency, sparse coding provides critical functional advantages. As Amit & Treves (1989) established, sparse activations reduce pattern interference, increasing memory capacity. More fundamentally, as demonstrated in our PAULA experiments, sparse connectivity is essential for dynamical stability. Dense coupling prevents homeostatic equilibrium, drowning out the local negative feedback loops required to form stable attractors.
5.2 Temporal Coding: Information Efficiency
Rate coding represents information in spike count (e.g., 10 spikes vs. 20 spikes). Temporal coding represents information in spike timing (e.g., spike at 10ms vs. 20ms). Time-to-first-spike (TTFS) coding demonstrates that most information can be carried by the timing of the first spike, with subsequent spikes providing refinement.
PAULA's recall dynamics exhibit TTFS-like efficiency. Correct answers appear in the top-3 hypotheses rapidly (16.8 ticks average), with full confidence (top-1 decision) requiring additional time (24.9 ticks). This 48% speedup for rough answers demonstrates temporal coding efficiency: fast decisions based on first-spike equivalent information, with slower deliberation for precision.
The R ↔ E link connects the cost of computation to the quality of the result. "Thinking harder" (longer recall time) costs more energy. The system must balance the metabolic cost of spiking against the need for accuracy.

6. Mathematical Formalization of the ALERM Framework
The ALERM framework formalizes the physical constraints governing self-organizing, biologically-plausible artificial intelligence. It views biological constraints, such as metabolic limits, spatial wiring limits, and temporal delays as necessary generative regularizers for intelligence.
Components' Equilibrium
The framework consists of 5 continuously interacting (morphing) components striving for thermodynamic equilibrium:
- A (Architecture): The physical maximum capacity of the spatiotemporal graph \( G(V, E, d) \). It acts as the Markov Blanket.
- L (Learning): The continuous differential update to the network's topology over time.
- E (Energy): The strict metabolic budget bounding the entire system, penalizing both spatial density and extended temporal processing.
- R (Recall): Active inference; the temporal integration process (ticks) spent sliding down an attractor basin.
- M (Memory): The actively sculpted subset of A (\( M \subseteq A \)); the crystallized limit-cycle pathways.
Variational Free Energy and Scale Invariance
ALERM abandons standard loss functions. Instead, at any arbitrary scale \( k \) (where \( k \) can be a single unit or a sub-network of \( N \) units), the system's sole objective is to minimize its Variational Free Energy \( F^{(k)} \), bounding its surprise given its environment:
Where \( o_i \) are sensory observations, \( s_i \) is the internal temporal state (spikes traversing delays), and \( q(s_i) \) is the current internal representation (active attractor basin).
The equations do not change between a single node and a network. Only the boundary of the Markov Blanket changes:
- Unit Level (\( N=1 \)): The observation \( o \) is the raw external input (e.g., sensory pixels).
- Network Level (\( N>1 \)): Through Nested Markov Blankets, the output state of an upstream neuron becomes the delayed input observation for a downstream neuron: \( o_i(t) = s_j(t - d_{j\rightarrow i}(t)) \). Here, the temporal transmission delay \(d\) is a parameter capable of dynamic topological adaptation.
ALERM Lagrangian
To represent the 5 components actively morphing to stabilize each other, ALERM is formalized as a constrained dynamical system using a Lagrangian (\( \mathcal{L} \)). The system reaches equilibrium (Learning stops, Memory crystallizes) when \( \nabla \mathcal{L}^{(k)} = 0 \).
Mathematical Couplings:
- Spatial Morphing (A ↔ M): Memory complexity is strictly bounded by the physical Architecture.
- Temporal Morphing (R ↔ E): Higher accuracy requires extended Recall time (\( R \)), which linearly burns the global Energy budget (\( E_{spent} = \gamma \cdot R \)).
- The Energy Regulator (\( \beta \)): The tradeoff parameter \( \beta \) is a function of available global energy. As \( E \) depletes, \( \beta(E) \) drops, forcing the network to sacrifice perfect accuracy and aggressively prune its topology into sparse, low-energy limit cycles.
Supervisors and Neuromodulation: \( M_0 \) and \( M_1 \)
To achieve generalized synchronization across a cell assembly, ALERM utilizes Volume Transmission of neuromodulators. These chemical supervisors track the aggregate derivative of the Free Energy landscape.
1. Fear / Stress Supervisor (\( M_0 \))
Tracks sustained prediction errors (Surprise). If the assembly fails to reach equilibrium, \( M_0 \) spikes.
Physical Effect: A high \( M_0 \) forcibly widens the temporal integration windows (\( t_{ref} \)) across the sub-network. This induces simulated annealing (anxiety), breaking rigid macro-attractors so the assembly can search for a new topological configuration.
2. Reward / Homeostasis Supervisor (\( M_1 \))
Tracks the velocity of error minimization (the "Savings Effect"). It spikes when the assembly discovers a harmonic resonance that rapidly reduces Free Energy.
Physical Effect: A high \( M_1 \) acts as a thermodynamic brake. It snaps all local \( t_{ref} \) gates shut simultaneously, driving weight updates to zero. This physically crystallizes the discovered multi-node limit cycle into permanent Memory.
Master Update Rule
The entire ALERM framework resolves into a single, unified dynamical rule. The physical change in the network's topology (\( \Delta G \)) at scale \( k \) is a function of sliding down the Free Energy gradient, gated entirely by the interactions between the Supervisors, and capped by the metabolic budget.
Interpretation: The network adapts by rolling down the energy landscape (\( -\nabla_s F \)), but learning physically cannot occur unless Reward outpaces Stress to pry open the plasticity gate, and the resulting structure strictly obeys the maximum metabolic energy bound (\( E_{max} \)).
7. Free Energy Principle and ALERM's Contribution
7.1 ALERM's Contribution: Empirical Proof of Coupling
How do these five components (Architecture, Learning, Energy, Recall, and Memory) fit together? The explanatory context is provided by the Free Energy Principle (FEP). Developed by Karl Friston, the FEP posits that all biological systems must minimize their free energy: an information-theoretic measure of "surprise" or prediction error. FEP is a very general principle: almost any adaptive system can be described as minimizing free energy in some sense. ALERM does not derive its value from the FEP label.
FEP Prediction: Architecture, Learning, Energy, Recall, and Memory must be coupled in any adaptive system. ALERM's Contribution: Empirical demonstration that disrupting any coupling degrades the system in ways that reveal the coupling's specific function.
ALERM's distinctive contribution is not organizing five concepts under a familiar umbrella: it is providing the first integrated empirical test of whether those five couplings are functionally necessary, and what each coupling specifically does. The ablation studies are direct evidence for the coupling thesis: removing homeostatic metaplasticity causes variance explosion (+365%, a proxy for increased free energy); removing sparsity causes convergence failure; removing multi-scale integration selectively drops complex-pattern performance. Each result names a coupling and specifies its function.
- Learning (L) minimizes surprise by updating the internal model to better predict sensory input
- Recall (R) minimizes surprise by refining beliefs about the current state through evidence accumulation
- Memory (M) provides stable internal models that generate predictions
- Architecture (A) determines the representational capacity of internal models
- Energy (E) constraints force efficient, parsimonious models (Occam's razor emerges from metabolic limits)
Mathematical proofs show that energy optimization induces predictive coding (Zhang et al., 2025), and extensions of the Information Bottleneck to multi-view processing (Westphal et al., 2026), firmly ground ALERM's architectural claims in established information theory.
7.2 PAULA as Concrete FEP Implementation
Our system minimizes a local approximation to free energy:
Three mechanisms work together to minimize free energy. First, learning drives weight updates proportional to prediction error, moving the system toward better predictions. Second, homeostatic regulation adapts neural gain to prevent runaway dynamics that would destabilize the network. Third, the network's natural settling dynamics converge toward attractor states that locally minimize free energy. These mechanisms operate concurrently, with each playing an essential role in maintaining stable, adaptive computation.
8. PAULA: A Computational Exemplar
8.1 Implementing ALERM Principles
PAULA (Predictive Adaptive Unsupervised Learning Agent) instantiates all five ALERM components in a working system:
Architecture (A): 6-layer network, 144 neurons, 25% sparse connectivity, graph-based micro-architecture enabling complex internal signal integration.
Learning (L): Integrates three mechanisms:
- Multiplicative synaptic updates: Δw = η × direction × error × w
- STDP directional gating for Hebbian association
- Homeostatic t_ref adaptation enabling stable learning
Energy (E): Sparse architecture (25% connections), sparse activations (~5-10% active), event-driven spiking computation, self-stabilizing dynamics minimize unnecessary updates.
Recall (R): Temporal integration with speed-accuracy tradeoff. Fast hypotheses (top-3: 16.8 ticks), deliberate decisions (top-1: 24.9 ticks), adaptive investment based on pattern complexity.
Memory (M): Attractor dynamics in weight × t_ref landscape. Cell assemblies emerge unsupervised. Stability measured by variance (53.82 baseline).
8.2 Empirical Evidence Through Ablation
We systematically ablated each mechanism and measured both performance and variance (a proxy for free energy / prediction surprise):
| Configuration | Performance | Variance | Key Finding |
|---|---|---|---|
| Baseline (full ALERM) | 84.3% | 53.82 | Optimal |
| Frozen t_ref (no homeostasis) | 80.4% | 250.22 | Marked variance increase (+365%) |
| Frozen weights (no learning) | 83.3% | 42.77 | Learning improves quality |
| No STDP (no Hebbian) | 82.4% | 76.70 | Association needed |
These results are evidence for ALERM's coupling thesis. Individual ablations reveal the function of each coupling: removing homeostasis causes variance explosion (+365%), revealing that the A ↔ L coupling depends on E-mediated gain control; removing sparsity causes global convergence failure, revealing that the A ↔ M coupling requires sparse architecture to function; removing multi-scale integration selectively drops complex-pattern performance while leaving simple patterns intact, revealing that the M ↔ R coupling is pattern-complexity-dependent.
In a tightly coupled system, individual ablations underestimate mechanism necessity because remaining components partially compensate. The all-ablation condition removes that compensation: all-ablation variance (110.05) supports that the mechanisms collectively produce stability that no proper subset can sustain, and that the intact system (variance 53.82) represents a qualitatively different dynamical regime than any ablation.
9. Conclusion
The ALERM framework validates that biological constraints are fundamental drivers of intelligence. Through the PAULA implementation, we have shown that Architecture, Learning, Energy, Recall, and Memory are not isolated systems but deeply interdependent components. Sparsity acts as a prerequisite for stable learning; metabolic limits enforce predictive efficiency; and temporal processing dynamically scales with pattern complexity.
By grounding the Free Energy Principle in the mechanics of spiking networks, ALERM moves beyond abstract theory. Alongside supporting discoveries in predictive coding and information theory, it offers a rigorous model of how local rules and biological limits naturally self-organize into stable, adaptive cognition.
ALERM provides a blueprint for building self-organizing, biologically-plausible AI systems. Unlike deep learning approaches that treat energy, architecture, and learning as independent design choices, ALERM shows how these are fundamentally coupled: energy constraints shape learning algorithms, which sculpt architecture, which determines memory capacity, which affects recall efficiency, creating feedback loops that self-organize toward free energy minima.
The framework generates testable predictions for neuroscience: fast homeostatic timescales should be necessary for stable learning, cortical heterogeneity should correlate with input complexity, and synaptic pruning should enable dynamical stabilization. For AI, ALERM suggests that biological constraints (sparse coding, local learning, metabolic budgets) are generative principles that could enable more robust, efficient, and generalizable systems.
Future work should test ALERM predictions in biological systems, scale PAULA to more complex tasks, and investigate whether the framework extends beyond sensory processing to higher cognition. Extension to convolutional architectures provides evidence that ALERM principles scale beyond MLP networks: preliminary results achieve 96.55% MNIST and 87.1% FashionMNIST accuracy without optimization, using the same PAULA neuron model and local learning rules with only the connectivity topology changed. This validates that the framework applies across architectural paradigms when appropriate structural priors are provided for the input domain.
The evolution from conceptual framework to empirically supported theory demonstrates that principled synthesis of neuroscience, information theory, and dynamical systems can advance both our understanding of intelligence and our ability to build intelligent systems.
Read the companion paper: For implementation details and comprehensive results, see PAULA: A Computational Substrate for Self-Organizing Biologically-Plausible AI.
10. References
10.1 Foundational Work
- Neural networks and physical systems with emergent collective computational abilities (Hopfield, 1982)
- Associative memory neural network with low temporal spiking rates (Amit & Treves, 1989)
- A theory of memory retrieval (Ratcliff, 1978)
- The free-energy principle: a unified brain theory? (Friston, 2010)
- Emergence of simple-cell receptive field properties by learning a sparse code for natural images (Olshausen & Field, 1996)
- The Organization of Behavior: A Neuropsychological Theory (Hebb, 1949)
10.2 Recent Advances (2024-2026)
- Predictive Coding with Spiking Neural Networks: A Survey (N'dri et al., 2025)
- Energy optimization induces predictive-coding properties in a multi-compartment spiking neural network model (Zhang et al., 2025)
- A Generalized Information Bottleneck Theory of Deep Learning (Westphal et al., 2026)
- Homeostatic synaptic plasticity as a metaplasticity mechanism - a molecular and cellular perspective (Li et al., 2019)
- Calcium dynamics predict direction of synaptic plasticity in striatal spiny projection neurons (Jędrzejewska-Szmek et al., 2016)
- EchoSpike Predictive Plasticity: An Online Local Learning Rule for Spiking Neural Networks (Graf et al., 2024)
- Deep Learning and the Information Bottleneck Principle (Tishby & Zaslavsky, 2015)
10.3 Neuroscience Evidence
- Deep Cortical Layers Are Activated Directly by Thalamus (Constantinople & Bruno, 2013)
- Phenotypic variation of transcriptomic cell types in mouse motor cortex (Scala et al., 2020)
- Regional differences in synaptogenesis in human cerebral cortex (Huttenlocher & Dabholkar, 1997)
- Homeostatic plasticity and STDP: keeping a neuron's cool in a fluctuating world (Watt & Desai, 2010)